
The emergence of RGB-D cameras offers the opportunity to easily develop 3D reconstruction systems for indoor scenes. However, the accuracy and the resolution of depth images are always constrained by the depth sensing techniques used in RGB-D cameras. Also, the raw depth images are often incomplete when surfaces are shiny, bright, transparent or far from the camera. Thanks to the new techniques to enhance the quality of depth image, it is easier to overcome these problems. In this blog post, we will mention one of those pipelines which is developed to improve 3D reconstruction quality of consumer-grade RGB-D cameras.
Overview
The overall pipeline to improve 3D holograms can be seen below. This pipeline can be divided into three main parts such as RGB-D image registration, depth super-resolution and completion and 3D reconstruction. In this post we will briefly walkthrough the RGB-D image registration and depth super-resolution and completion parts and show some results.

RGB-D Image Registration
Depth and color images need to be registered under a unified camera coordinate system, since they are captured by different sensors of Kinect. The resolution of original unregistered depth and color images are 512×424 and 1920×1080 respectively. After applying image registration registered depth and camera images are in the same camera coordinate system. After registering images using transformation and intrinsic matrices of sensors, we end up with a low resolution depth image in the color camera coordinate system. You can see the unregistered and registered depth-color image pairs below, respectively a and b.

Depth Super-Resolution and Completion
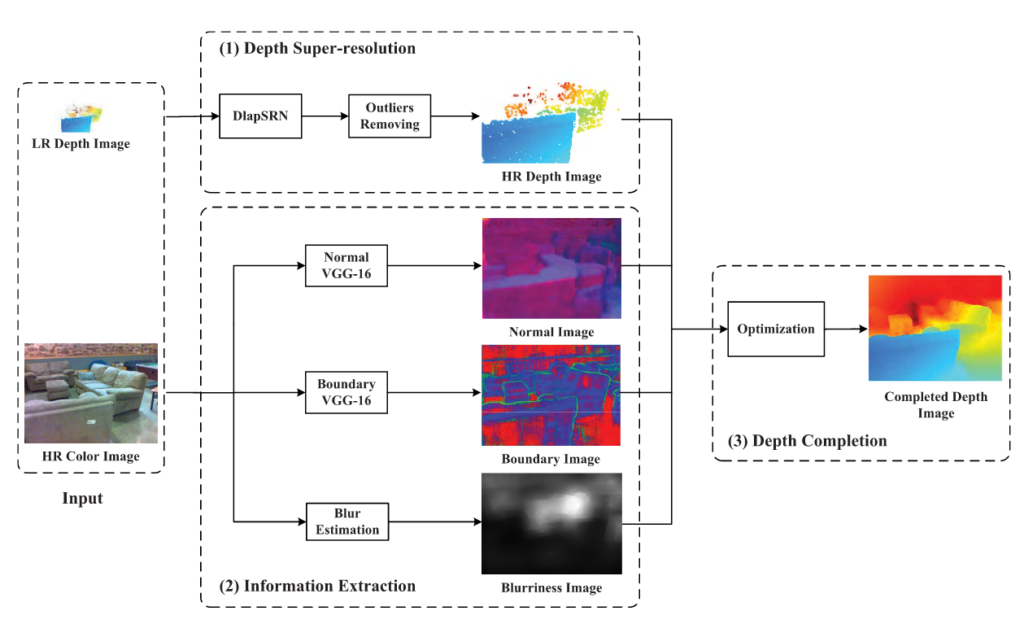
This part consists of three stages: depth super-resolution, information extraction, and depth completion.
Depth Super-Resolution
The input registered low resolution image is enhanced to a high resolution depth image using a depth laplacian super-resolution network called DlapSRN, which uses the laplacian pyramid network as base and is composed of two branches: feature extraction and depth image reconstruction. Also, the outliers in the predicted high resolution depth image are detected and removed based on gradient saliency.
Information Extraction
The high resolution color image is used to generate the surface normal, occlusion boundary and blurriness image. Surface normal and occlusion boundary images are predicted through two fully-connected neural networks, which are VGG-16 in the paper. These images will be used with high resolution depth image in order to complete the final depth image.
Depth Completion
The goal of the depth completion is to complete the high-resolution depth image with the predicted surface normals, occlusion boundaries and blurriness image. Surface normals and occlusion boundaries are employed to get local properties of the surface geometry, while image blurriness denotes the qualities of surface normals and occlusion boundaries predicted from the high resolution color image. Then we combine them through global optimization (sparse Cholesky factorization) to complete the depth image for all pixels in a consistent solution.
The overall view of the depth super-resolution and completion part can be seen below.
In the figure below, you can see the input low resolution depth and high resolution color images (a), the raw depth image and corresponding point cloud with it (b) and enhanced depth image and corresponding point cloud calculated with it (c).

Conclusion
In this blog, we examined a depth super-resolution and completion method which is a neural network based pipeline and can be applied to low quality depth images captured by consumer-grade RGB-D cameras such as Kinect, Realsense etc. for high quality 3D hologram or volumetric video generation.